
 https://orcid.org/0000-0001-7229-5651
https://orcid.org/0000-0001-7229-56511. INTRODUCCIÓN
Si bien los estudios de traducción basados en corpus no son novedad y están en continuo crecimiento (Laviosa, 2002), el uso de herramientas digitales para analizar traducciones todavía carece de arraigo, en particular en lo que concierne al análisis estilístico de traducciones literarias, que necesitan de mayor definición de cuadros metodológicos (Novodvorksi, 2015; Saldanha, 2011). Especialmente en el ámbito de la traducción de literatura infantil, donde las dificultades a las que hace frente el traductor a la hora de traspasar el texto a la lengua de destino son mayores y particulares por el tipo de lector destinatario y tendrán consecuencias sobre las estrategias de traducción que utilice (Oittinen, 2000; Coillie & Verchueren, 2014; Zohar Shavit, 1981). Nuestro interés en escoger obras pertenecientes a este género se basa en proponer nuevos modelos de análisis para futuros trabajos de investigación en este campo.
Como ya hemos dicho antes, los trabajos que analizan traducciones de literatura infantil parten de la base de que las decisiones del traductor están condicionadas por las limitaciones en conocimientos lingüísticos y culturales de su público lector. Se han redactado múltiples libros, tesis doctorales, artículos y trabajos de fin de carrera sobre los aspectos teóricos y análisis de traducciones de literatura infantil que parten inicialmente desde un análisis cualitativo de las obras estudiadas.
Si bien consideramos el análisis cualitativo es fundamental para los trabajos de estudios de traducciones, también creemos que el uso de herramientas digitales para el análisis cuantitativo de estilo puede permitir observar estrategias de traducción que no se harían notar en un primer análisis humano. Además, el uso de herramientas digitales para analizar un corpus de texto permite al investigador trabajar con volúmenes de texto mucho mayores, con lo que podría ampliar su campo de análisis: análisis diacrónicos de distintas traducciones de una misma obra, análisis de traducciones en distintos idiomas, o análisis de series completas de obras de literatura infantil son algunos de las posibilidades que nos ofrecen estas herramientas.
En este artículo nos basamos en Malmkjaer (2004) quien, en el ámbito de estudios de estilo de traducción, propone una metodología de análisis consistente en el estudio de patrones recurrentes en relación con el texto de origen y la traducción.
Como ya hemos dicho anteriormente, este uso de herramientas digitales para el análisis cuantitativo de traducciones puede servir al investigador de punto de partida para una investigación inductiva posterior. Los resultados obtenidos con estas herramientas nos permitirían formular hipótesis que trataríamos de verificar o desmentir posteriormente a través de una aproximación cualitativa a los textos. Para este artículo, nos proponemos realizar una comparación entre diferentes traducciones utilizando tres herramientas: Stylo1, Gephi2 y Sketch Engine. El objetivo es de observar qué nos puede aportar su uso al análisis de traducciones y si están al alcance de cualquier estudioso de la literatura y de la traducción.
Hemos seleccionado un corpus de cinco obras de literatura infantil para nuestro análisis inicial con herramientas digitales: dos originales en francés y tres traducciones al español.
En primer lugar, hemos seleccionado la novela para niños Les malheurs de Sophie de la Condesa de Ségur (1858) y dos de sus traducciones al español: Las desventuras de Sofía (en un ejemplar de edición de 1979, con traducción de 1970) y Las desdichas de Sophie (edición y traducción de 2018).
De Les malheurs de Sophie, nos consta que existen en total siete traducciones diferentes (Fraga, 2017): Las travesuras de Sofía (1925, traducción de Teodomiro Moreno Durán), Las desgracias de Sofía (1943, traducción de Delia Piquérez) y Las desgracias de Sofía (1946, traducción de Matilde Ras), Las desventuras de Sofía (1979, traducción de Rori Conde Muñoz) y Las desdichas de Sophie (2018, traducción de Traducciones Imposibles). Según lo indicado en el ejemplar de 2018, la traducción de la obra de la Condesa de Ségur se basa en un trabajo preliminar llevado a cabo por estudiantes de Traducción e Interpretación, por lo que no tenemos a un autor único de la traducción.
La obra de la Condesa de Ségur se enmarca en la literatura infantil de carácter pedagógico e iniciático, que persigue, como dice Brown (2008), un conformismo hacia los valores de la cultura dominante. En Les malheurs de Sophie, la protagonista, una niña de 4 años hija de una familia acomodada en la Francia del siglo XIX y que vive en una mansión en el campo, aprende las consecuencias de sus actos y, en ocasiones, recibe castigos por sus faltas. Cada uno de sus episodios, por lo general muy cortos, están escritos con un estilo claro en los que suele predominar el diálogo y hasta llegan a parecer diálogos teatrales en los que las acciones de los personajes están descritas entre paréntesis junto a su nombre. Aunque podemos apreciar una cierta modernidad en lo que respecta a la mezcla de estilos en la obra de Ségur, bien es cierto que la temática poco responde a tendencias contemporáneas en la literatura infantil, sobre todo en cuanto a la manera, un tanto explícita, en la que se presentan las lecciones que el lector debería incorporar a su comportamiento.
La obra de la condesa de Ségur presenta un carácter serial, que corresponde al hecho de que su obra fuera publicada en la revista infantil La semaine des enfants antes de ser publicada como libro (Fraga, 2017). Estas obra, aunque pueda haber tenido una influencia indirecta y directa en la literatura infantil española del siglo XX (sobre todo a principios y mediados de siglo), no parece ser una referencia clara para el potencial lector del siglo XXI. Sin embargo, que esta obra haya sido traducida en diversas ocasiones al español nos permite llevar a cabo un análisis cuantitativo diacrónico de las traducciones.
El segundo conjunto de obras que componen nuestro corpus es Les nouveaux malheurs de Sophie (2001) de Valérie Dayre, y su traducción en español Las desventuras de Sophie (2006, traducción de Isabelle Marc). La decisión de añadir este conjunto de obras al análisis se debe a la clara relación referencial que existe entre esta segunda obra y el trabajo de la Condesa de Ségur. Aunque no se trate de una continuación o una reactualización de la obra de Ségur, adaptada a tiempos y sensibilidades modernas, la obra de Dayre hace ese interesante guiño intertextual al lector francés.
En el libro de Dayre también podemos encontrar una lección para el lector, aunque este elemento no está presentado de manera tan explícita como en Ségur. Ni siquiera se trata de un mismo tipo de aprendizaje: al contrario que la primera Sophie, cuyas lecciones están centradas en su comportamiento a través de un sistema dicotómico bueno/malo y recompensa/castigo, el aprendizaje de la Sophie moderna es más sutil y centrado en su relación con el entorno y las personas que la rodean. En el final de su historia, aunque el lector puede deducir una moraleja respecto a los acontecimientos que se relatan, no está presentada de manera explícita al lector.
Terminaremos el artículo con un balance de la utilidad y las limitaciones de estas herramientas, así como de los resultados obtenidos de la comparación cuantitativa de las traducciones.
2. METODOLOGÍA
Para este análisis utilizaremos tres herramientas digitales de análisis de corpus: Stylo, Gephi y Sketch Engine. El primero permite realizar una variedad de análisis estilométricos. Aunque podemos obtener listas de frecuencia, matrices de distancias e imágenes en alta resolución de los análisis llevados a cabo por Stylo, nos interesa su uso en relación con el software de análisis y visualización de gráficos Gephi. Por su parte, este nos permite visualizar los patrones de similitudes y diferencias existentes, al tiempo que muestra las redes de relación entre ellos y la fortaleza o debilidad en las similitudes existentes entre cada uno de los elementos analizados. Podemos así trabajar en un solo proyecto con un corpus de textos multilingüe.
Estas relaciones y patrones de similitudes y diferencias son resultado del análisis de las palabras más frecuentes en cada uno de los textos que componen el corpus de análisis. Kenny (1982) utiliza el término stylistic fingerprint para referirse a los elementos que caracterizan el estilo de un autor, particularmente en la manera particular que ese autor tendría de combinar las palabras frecuentes. Otros autores como Burrows (1987) y McKenna et al. (1999) también han asentado la importancia del análisis de las palabras frecuentes para el estudio del estilo en la literatura.
En Stylo y Gephi hemos creado un proyecto que incluye los cinco textos que componen nuestro corpus. Nuestra intención es observar las relaciones que se establecen entre, por un lado, los textos originales y sus traducciones y, por otro lado, la obra de Ségur frente a la obra de Dayre. Para ello, hemos establecido los siguientes parámetros en Stylo para obtener nuestros resultados de análisis, contado palabras y n-grams con tamaño mínimo de 1 y establecido una lista de palabras más frecuentes con un mínimo de 100 y un máximo de 1.500. Con ellos la herramienta crea una lista de palabras más frecuentes del corpus completo y las analiza. Luego, seleccionamos el método de cluster analysis para obtener nuestros resultados. Además de esto, Stylo proporciona también un archivo donde se indican los vínculos de relación entre las cinco obras que componen el corpus. Este es el documento que hemos utilizado posteriormente para obtener nuestra visualización en Gephi.
Para complementar nuestro análisis, hemos utilizado tres de las funciones de Sketch Engine, Wordlist, que genera listas de frecuencia de términos y permite observar las colocaciones y otros términos que rodean al término buscado; Word Sketch y Word Sketch Difference que permiten hacer comparaciones entre dos términos a través del contraste de las colocaciones de cada uno de estos términos.
3. RESULTADOS DE ANÁLISIS CON STYLO Y GEPHI
En los resultados obtenidos en Stylo, observamos (figura 1) cómo las traducciones de la obra de Ségur aparecen separadas del original francés que, sin embargo, parece compartir mayores lazos de similitudes con la obra de Dayre y su traducción al español.
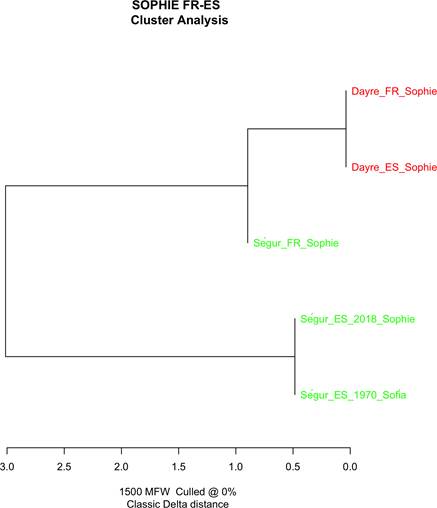
Fuente: elaboración propia.
La visualización con Gephi incluye los vínculos entre los textos pertenecientes a distintos autores.
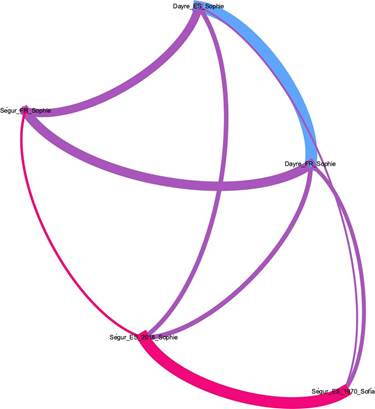
Fuente: elaboración propia.
Como podemos ver (figura 2), la jerarquía de relaciones entre las distintas obras que conforman el corpus queda confirmada. De nuevo observamos cómo el texto francés de Ségur presenta una fuerte relación con la obra de Dayre, así como su separación con respecto a sus dos traducciones. En esta visualización podemos observar, además, que entre las dos traducciones españolas de Ségur existen también vínculos de relación respecto a la de Dayre (original y traducción). Mientras que la relación entre la traducción de 2018 con los dos textos de Dayre es equivalente a nivel de similitud, la traducción de 1970 presenta un vínculo más débil con la traducción española de Dayre que con el texto original francés.
Las dos traducciones al español de Ségur muestran una fuerte relación entre sí, al igual que el texto de Dayre en francés y su traducción. Sin embargo, no podemos observar ningún lazo entre la traducción española de 1970 de Ségur y el original en francés. Mientras que la relación entre la traducción de 2018 y el original muestra un vínculo débil, con un grado de similitud menor que con la obra de Dayre.
Esta separación y falta de vínculo entre el original francés y la traducción de 1970 nos lleva a plantear hipótesis de por qué esto ocurre: que la traducción haya modificado u omitido elementos del texto original, o que no se trate de una traducción, sino de una adaptación del texto original para el lector español por diversos motivos que puedan estar relacionados con la adecuación al público lector destinatario.
Efectivamente, entre la traducción de 1970 y la traducción de 2018 observamos un vínculo fuerte. Entre la traducción de 2018 y el texto original sí que podemos observar que existe cierto grado de relación que, aunque débil, se posiciona en un punto intermedio entre el texto original y la traducción de 1970. La visualización de los vínculos existentes entre las tres obras nos permite plantear, como conclusión provisional, que el texto de 2018 podría haber tomado inspiración de la primera traducción en lo que respecta al traspaso al español de la obra francesa, pero que habría mantenido mayor grado de fidelidad al texto original en comparación con el primero.
En lo que respecta a la obra de Dayre, como ya hemos mencionado, los dos textos (original y traducción) presentan un vínculo fuerte de relación entre sí. Esta proximidad entre ambos textos nos lleva a otra conclusión provisional: la traducción presenta un fuerte grado de apego al texto original.
4. RESULTADOS DE ANÁLISIS CON SKETCH ENGINE
A partir de los resultados que hemos obtenido con Stylo y Gephi, nos hemos centrado en el análisis con Sketch Engine en la obra de Ségur y de sus dos traducciones. Hemos introducido separadamente cada uno de los textos en Sketch Engine, creando así tres proyectos de análisis distintos. Nos interesa determinar si en Sketch Engine podemos detectar elementos que nos ayuden a confirmar los resultados que hemos obtenido con Stylo y Gephi.
En cada uno de los corpus, hemos realizado las siguientes búsquedas: con Wordlist, hemos generado dos listas diferentes de las categorías gramaticales de sustantivos y adjetivos, centrándonos en el análisis de los primeros 50 términos de las listas; con Word Sketch, hemos llevado a cabo búsquedas con los nombres de los personajes, particularmente Sophie y Paul, además mamá/ maman y otras variaciones de este término como madre; con Word Sketch Difference, hemos realizado búsquedas para combinaciones de términos como son Sophie-Paul, Sophie-mamá/maman y Paul-mamá. Tanto para Word Sketch como para Word Sketch Difference, nos hemos centrado en la visualización de los 10 primeros términos según su frecuencia de apariciones para cada uno de los corpus. Pasaremos a analizar cada uno de los resultados que hemos obtenido con estas herramientas.
Entre los 10 primeros sustantivos del corpus francés, tres de ellos son nombres propios: Sophie primero (frecuencia 757), Paul segundo (frecuencia 431) y Réan en tercer lugar (frecuencia 210). Podemos destacar también una prevalencia de personajes femeninos sobre los masculinos: a excepción de Paul, que podríamos considerar como protagonista segundo de la obra, el otro único personaje masculino más mencionado es el criado Lambert (n.º 22, frecuencia 43).
No encontramos entre los primeros cincuenta sustantivos menciones a los padres de Sophie y de Paul, ya que el lema monsieur, que aparece en el puesto número 5 de la lista, es en realidad la forma lema de madame y mademoiselle. Tampoco encontramos entre estos primeros términos ninguna aparición de père. Sin embargo, sí que podemos encontrar una mención en la traducción de 1970, siendo el único corpus de los tres en el que el término padre aparece entre los primeros cincuenta términos. Este corpus también es el único de los tres donde aparecen los términos primo y prima.
En la traducción española de 2018 podemos observar un ligero aumento en la frecuencia de menciones de Sophie con respecto al texto original (779 vs 757). Observamos una disminución en la frecuencia del término mamá en esta traducción con respecto al original (puesto número 5). Esto es debido a la variación en la traducción, ya que en ocasiones se ha optado por traducir maman como madre, que aparece en el puesto número 7, con una frecuencia 126. En el corpus de 1970, el maman francés también se ha convertido alternativamente en mamá o madre.
En la traducción de 1970, se ha optado por una naturalización al español de los nombres propios. Así, Sophie y Paul se han convertido en Sofía y Pablo, al igual que otros nombres de personajes que también han sido traducidos por su equivalente español: Madeleine se convierte así en Magdalena, y Elizabeth se convierte en Elisabet. Sin embargo, otros personajes han conservado su nombre original francés, como es el caso del criado Lambert.
En la traducción de 2018, notamos también la aparición de dos términos que no estaban en la lista de sustantivos del texto original: niñera (n.º 11, frecuencia de 86) y tata (n.º 34, frecuencia de 28). En realidad, es que Sketch Engine ha interpretado las apariciones de la bonne en el texto francés como un adjetivo y no como un sustantivo.
Al igual que en el caso de maman, esta traducción ha optado por utilizar dos términos diferentes para hacer referencia a la niñera de Sophie. En una lectura más detenida, observamos que el uso de tata ocurre en la mayoría de ocasiones en situaciones en las que Sophie se dirige directamente a su niñera o habla de esta con otros personajes. El uso de este término, de carácter más familiar, aporta al lector de la traducción la impresión de una relación de cercanía entre la niña y su cuidadora.
En la traducción de 1970, tan solo encontramos entre los primeros cincuenta términos, el uso de niñera (en octava posición en la lista, con una frecuencia de 87) y, al contrario que en la traducción de 2018, el término tata es utilizado con menor frecuencia y ocupa el puesto 87. A pesar de esto, el hecho de encontrar también el término tata en la traducción de 1970 nos plantea la posibilidad que esta traducción haya servido como inspiración para la versión de 2018, que habría reproducido y ampliado el uso de tata.
Otros dos elementos importantes corresponden a la categoría de animales. En el corpus de 1970, observamos la aparición en la lista de términos de la palabra perro (n.º 45, frecuencia 23), que no aparecía entre los primeros 50 sustantivos del texto original, y la desaparición de poisson de la lista. En segundo lugar, el poulet francés se ha transformado en pollito en la traducción. El uso de un diminutivo otorga un carácter más informal y cariñoso, una estrategia que se ha reproducido también en la traducción de 2018.
En lo que se refiere a los adjetivos y en términos de frecuencia, los dos primeros adjetivos que encontramos en lista del corpus francés son bon y petit. Para la traducción de 2018, el adjetivo bueno sigue encabezando la lista de adjetivos más frecuentes en la traducción, aunque petit, que ostentaba la segunda posición en el corpus francés, aquí cae hasta un cuarto puesto y pasa de una frecuencia de 156 a tan solo 46. La traducción de 1970, al contrario, sí que mantiene en las dos primeras posiciones los adjetivos bueno y pequeño, como una traducción más ceñida al estilo de expresión del texto original.
Otro aspecto que nos llama la atención es la frecuencia de términos relacionados con el campo semántico del comportamiento, ya sea negativo o positivo. Entre los primeros cincuenta términos encontramos adjetivos como méchant, mauvais, honteux, obéissant, tranquille y charmant. También encontramos adjetivos en relación con los sentimientos: el primero en esta lista es triste, pero también malheureux, content, ennuyeux, heureux y furieux.
Podemos observar una mayor frecuencia de adjetivos relativos a comportamientos negativos en la traducción de 2018 con respecto al original francés. Adjetivos como burlón y cruel no aparecen ni siquiera entre los primeros 50 términos del corpus francés. En sentido contrario, no encontramos un equivalente en el corpus español para el adjetivo honteux, que se encuentra en el puesto 22 del corpus francés. Otro adjetivo para el que tampoco encontramos equivalente en el corpus español de 2018 es el de gourmand –tenemos que adentrarnos hasta las posiciones 151 y 152 para encontrar sus equivalentes en la traducción española (glotón y goloso).
En la traducción de 1970 notamos que la carga semántica negativa de los adjetivos que describen el comportamiento es menor que en la traducción de 2018. Entre las primeras 50 posiciones observamos adjetivos como terrible, en el puesto 26, travieso, en el puesto 44, así como malo en el puesto número seis y mal en el puesto número 32 además de horrible en el puesto 35. Sin embargo, no encontramos menciones aquí a desobediente u obediente que sí aparecen en la traducción de 2018, al igual que en el texto original. Tampoco encontramos ninguna traducción del adjetivo francés gourmand, ni observamos ninguna aparición de adjetivos como burlón y cruel.
Si ahora nos centramos en el análisis de los nombres propios con Word Sketch y Word Sketch Difference, obtenemos las siguientes visualizaciones:

Fuente: elaboración propia.

Fuente: elaboración propia.
Así comparando los tres corpus, notamos, en primer lugar, que, en los tres textos, la asociación principal de Sophie es con su primo Paul, en estructuras de frase de Sophie y/o. Tanto en el texto original como en la traducción de 2018, Paul es el único otro personaje relacionado con Sophie en las visualizaciones de Sketch Engine. Sin embargo, en la traducción de 1970, también encontramos menciones a niñera y señor en la lista de Sophie y/o. No encontramos, sin embargo, en ninguna de estas visualizaciones, menciones a la madre de Sophie.
En lo que respecta a los verbos, el verbo con mayor frecuencia en las estructuras de frase que tienen a Sophie como complemento de la frase es el verbo decir/dire, en el corpus original y en la traducción de 2018. Sin embargo, en la traducción de 1970, el verbo que aparece con mayor frecuencia es el de contestar. Encontramos mayor riqueza léxica en los verbos pertenecientes al campo semántico del discurso en esta traducción: contestar, exclamar, gritar, suspirar y decir; mientras que entre los verbos de discurso de la traducción de 2018 tan solo encontramos decir y responder.
Entre los verbos que tienen a Sophie como sujeto, el único verbo del campo semántico del discurso en el original francés es dire. De nuevo notamos mayor riqueza léxica en la traducción de 1970, con verbos como exclamar, decir e interrumpir. En la traducción de 2018, de nuevo, solo observamos los verbos responder y decir.
Curiosamente, en la relaciones de términos con Paul encontramos una mayor riqueza léxica. Si bien el término que con mayor frecuencia se asocia a Paul sigue siendo Sophie, éste presenta mayor relación con otros personajes. En la lista de Paul y/o podemos encontrar menciones a tante, Réan, ami y camarade en el texto original. En la traducción de 1970, los sustantivos con los que principalmente se relaciona son sustantivos de personas o de animales: niñera, mamá, prima, madre, perro, tío. La traducción de 2018 es la que menos relaciones presenta: a Paul se le relaciona únicamente con niñera, tío, amigo y burro.
En lo que respecta a los verbos, las traducciones españolas son más ricas en verbos del campo semántico del discurso que el original francés. Encontramos en la traducción de 1970 verbos como decir, contestar, responder, preguntar, intervenir y observar, mientras que en la traducción de 2018 aparecen los verbos responder, gritar y exclamar.
Por otro lado, las traducciones españolas de Les malheurs de Sophie optaron por utilizar mamá y madre, por lo cual decidimos aproximarnos a ambos términos en Word Sketch.
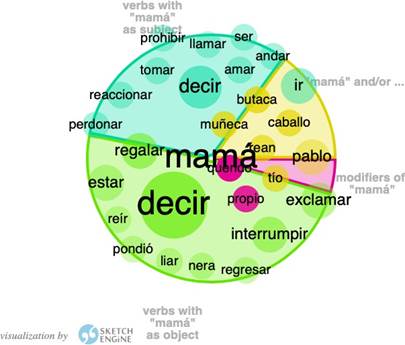
Fuente: elaboración propia.
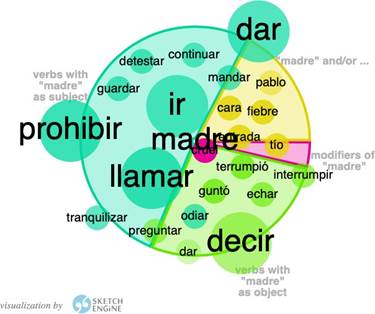
Fuente: elaboración propia.
Llama poderosamente la atención el ámbito semántico disciplinario. En el corpus francés, el verbo défendre es uno de los que aparecen con mayor frecuencia, después de dire. En ambas traducciones podemos encontrar los verbos regañar y prohibir. Observamos, sin embargo, que la mayor frecuencia de aparición de estos verbos es en relación con el término madre. Tanto en la traducción de 2018 como en la traducción de 1970, prohibir es uno de los verbos con mayor frecuencia de aparición. Sin embargo, con el término mamá, la frecuencia de aparición de prohibir disminuye en la traducción de 1970 y desaparece en la traducción de 2018.
También hemos observado cómo en ninguno de los corpus encontramos relación entre los términos maman / mamá / madre y Sophie. En el corpus francés, las únicas relaciones con sustantivos de personas se establecen con enfant, tante y homme. El único corpus en el que aparece relación con algún personaje es la traducción de 1970, donde aparece el nombre de Paul (Pablo, en este caso, ya que el nombre se ha naturalizado al español).
Fijémonos precisamente en esas asociaciones de términos relacionados con Sophie o con mamá-madre:
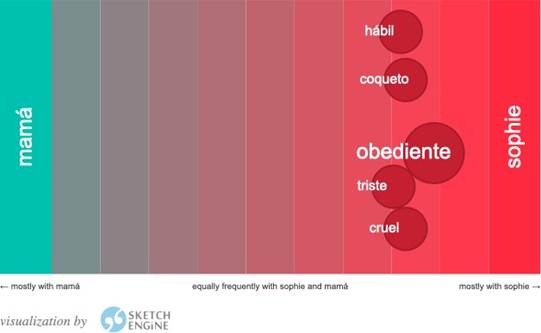
Fuente: elaboración propia.

Fuente: elaboración propia.
Para el tipo de frases correspondientes a la estructura Sophie/mamá es/está + adjetivo encontramos bastante diferencia entre las dos traducciones al español: mientras que en la traducción española de 2018, el término mamá no presenta asociaciones a modificadores en comparación con Sophie, a quien se le asocian los términos hábil, coqueto, obediente, triste y cruel; en el caso de la traducción de 1970, podemos observar que el término mamá sí que está presente en estructuras sintácticas Sustantivo + es/está + adjetivo, al igual que Sophie y comparte con ella el adjetivo triste. Sin embargo, los otros términos con los que se relacionan son opuestos, tanto a nivel de frecuencia como de semántica: si a Sophie se la relaciona con mal y triste, a su madre se la relaciona con bueno y contento.
Respecto a la relación Paul-mamá/madre, también observamos tendencias contrarias entre las dos traducciones al español en la estructura de frase Paul/mamá + ser/estar + adjetivo. Si en la traducción de 1970, mamá es el único de los dos términos al que se le asocian adjetivos, en la traducción de 2018 nos encontramos con la situación contraria. Paul es el término al que se asocian con más frecuencia adjetivos, en este caso mejor, pálido, y triste.
5. CONCLUSIONES
A partir de los resultados obtenidos en Stylo y Gephi, llegamos a las siguientes conclusiones provisionales respecto a las traducciones analizadas:
- La traducción de la obra de Dayre presenta mayor grado de apego al texto original, sin grandes cambios en forma y contenido de la obra traducida con respecto al original.
- La distancia que observamos entre la traducción de 1970 y el texto original puede corresponder a un trabajo de traducción en el que el texto original ha servido como base para una adaptación de su contenido.
- El vínculo que existe entre la traducción de 2018 y la traducción de 1970 hace pensar que esta puede haber servido como referencia para aquella pero que, al contrario que la traducción de 1970 haya mantenido un grado mayor de correspondencia con el texto original.
El análisis con Sketch Engine nos ha permitido reforzar esas conclusiones provisionales, ya que hemos podido observar cómo la traducción de 2018 reproduce ciertos elementos que ya encontrábamos en la traducción de 1970 y cómo se deshace también de otros.
En cualquier caso, son conclusiones provisionales respecto a las elecciones de traducción que podremos confirmar en un análisis cualitativo posterior de los textos, pero que tienen la ventaja de haber sido obtenidas muy rápido y ofrecernos unas preciosas pistas de trabajo para un análisis cualitativo detenido. Esto puede ser de gran utilidad para analizar traducciones literarias: frecuencias de verbos, adjetivos, de sustantivos, que podrían pasar desapercibidas en una lectura más profunda del texto, se hacen visibles rápidamente gracias al uso de estas herramientas.
Más aún, el uso de herramientas digitales presenta especial interés para trabajos de análisis diacrónico o de traducciones multilingües donde se comparen diferentes versiones de un mismo texto original, pues permite abarcar un corpus de textos tan amplio como sea necesario.
Sketch Engine ofrece una gran variedad en herramientas de análisis que permiten al investigador obtener resultados sin tener que recurrir a múltiples programas. Además de las funciones que hemos utilizado para este artículo, Sketch Engine también ofrece la posibilidad de estudiar los sinónimos o palabras similares de un corpus (con la función Thesaurus), analizar expresiones (n- grams), extraer la terminología del corpus (Keywords) o buscar ejemplos del uso dentro del texto (Concordance).
Por otro lado, Stylo y Gephi son programas que no necesitan ninguna afiliación a un centro de estudios o pagos de subscripciones, con lo que pueden ser descargados y utilizados libre y gratuitamente por cualquier usuario interesado en ellas.
Sin embargo, durante nuestro análisis, hemos encontrado ciertas limitaciones que es también necesario mencionar. En primer lugar, durante nuestro trabajo con Sketch Engine, pudimos observar situaciones en las que la herramienta ha realizado una interpretación errónea de las categorías gramaticales de algunos términos, lo cual podría conducir a resultados de análisis equivocados. Este caso en específico lo hallamos trabajando con nuestro corpus francés, como hemos mencionado anteriormente en el artículo. Aunque Sketch Engine proporciona la posibilidad de trabajar con corpus en múltiples idiomas, sería interesante observar en futuros trabajos si este problema de interpretación ocurre también en corpus en otras lenguas que no sean el inglés, el francés o el español.
En segundo lugar, y no por ello menos importante, también debe ser tenida en cuenta la diferencia que existe en el nivel de simplicidad de uso de cada una de estas herramientas que hemos utilizado. Mientras que la interfaz de Sketch Engine favorece un aprendizaje más intuitivo para un usuario novel, las de Stylo y Gephi carecen de esa simpleza para el usuario inicial, que podría encontrar menos accesible el uso de estas herramientas ya que, también, la posibilidad de error en los resultados iniciales es bastante alta.
A pesar de estos inconvenientes, la accesibilidad y la amigabilidad de estas herramientas hacen de ellas un aliado excelente de cualquier filólogo, de cualquier profesor, hasta en la enseñanza secundaria. Con todo, la conclusión es clara: la rapidez en la obtención de resultados, los grandes volúmenes posibles de texto a tratar, así como la facilidad de uso de estas herramientas proporcionan al investigador una base inicial de trabajo para cualquier investigación cualitativa posterior.
REFERENCIAS BIBLIOGRÁFICAS
Bastian, M., Heymann, S., & Jacomy, M. (2009). Gephi: An Open Source Software for Exploring and Manipulating Networks. Proceedings of the International AAAI Conference on Web and Social Media, 3(1), 361-362. https://ojs.aaai.org/index.php/ICWSM/article/view/13937
Brown, P. (2008). A Critical History of French Children’s Literature: 1830 - Present. Routledge.
Burrows J. F. (1987). Computation into Criticism: A Study of Jane Austen’s Novels and an Experimental Method. Clarendon.
Coillie, J., & Verschueren, W. (Eds.) (2014). Children’s Literature in Translation. Challenges and Strategies. Routledge.
Dayre, V. (2001). Les nouveaux malheurs de Sophie. L’école des loisirs.
Dayre, V. (2006). Las desventuras de Sophie (I. Marc, trad.). Ediciones SM.
Eder, M., Rybicki, J., & Kestemont, M. (2016). Stylometry with R: a package for computational text analysis. R Journal, 8(1), 107-21. https://doi.org/10.32614/RJ-2016-007
Fraga, M. J. (2017). Las aventuras de Sophie en España: recepción de las novelas de la condesa de Ségur. Çédille. Revist de estudios franceses, 13, 105-208.
Kenny A. (1986). A Stylometric Study of The New Testament. Clarendon.
Laviosa, S. (2002). Corpus-based translation studies: theory, findings, applications. Rodopi.
Malmkjaer, K. (2004). Translational stylistics: Dulcken’s translations of Hans Christian Andersen. Language and Literature, 13(1), 13-24.
McKenna, W., Burrows J., & Antonia, A. (1999). Beckett’s Trilogy: Computational Stylistics and the Nature of Translation. Revue informatique et statistique dans les sciences humaines, 35(1-4), 151-171.
Novodvorski, A. (2015). Estudios de la traducción basados en corpus. Aspectos metodológicos para el análisis del estilo. Metodologías y aplicaciones en la investigación en traducción e interpretación con corpus, pp. 117-138. Universidad de Valladolid.
Novodvorski, A. (2015). Estudios de la traducción basados en corpus. Aspectos metodológicos para el análisis del estilo. En M. T. Sánchez Nieto, S. Álvarez Álvarez, V. Arnáiz Uzquiza, M. T. Ortego Antón, L. Santamaría Ciordia, & R. Fernández Muñiz, Metodología y aplicaciones en la investigación en traducción e interpretación con corpus (pp. 117-138). Universidad de Valladolid. http://uvadoc.uva.es/handle/10324/16454
Oittinen, R. (2000). Translating for Children. Garland Publishing INC.
Saldanha, G. (2011). Translator Style Methodological considerations. The Translator 17(1). 25-50.
Ségur, Condesa de (1853). Les malheurs de Sophie. TV5Monde. htps://bibliothequenumerique.tv5monde.com/ livre/169/Les-Malheurs-de-Sophie
Ségur, Condesa de (1979). Las desventuras de Sofía (R. Conde Muñoz, trad.). Editorial AFHA Internacional.
Ségur, Condesa de (2018). Las desdichas de Sophie. Taketombo Books.
Zohar Shavit (1981). Translation Of Children’s Literature as A Function of its Position in the Literary
Polysystem. Poetics Today. 2(4), 171-179.